 Envel Le Hir
Envel Le HirA Dataiku DSS plugin to query SPARQL endpoints
Dataiku Data Science Studio (Dataiku DSS) is a collaborative data science software. The free edition is powerful enough to work on small data sets and to let you save a lot of time in analysis.
While you can already connect to SPARQL endpoints using the HTTP connector, it’s not straightforward nor convenient because you have to encode your query in the URL. This is why I made a simple plugin that allows you to seamlessly query SPARQL endpoints, by only having to specify the URL of the endpoint and your query. At the moment, the plugin works for SELECT statements only. The plugin is available on Github under free license (AGPLv3).
Installation
The first step is to add the plugin to your Dataiku DSS instance. Go to Administration > Plugins and then to the Advanced tab. Afterwards, you can either:
- Download the latest version of the plugin and upload the file you just downloaded.
- Clone the Git repository.
As the plugin has dependencies, you will be asked to create a dedicated code environment. Select Managed by DSS (recommended), let Use Conda unchecked, select PYTHON27 (the plugin also works with more modern versions of Python, but as of Dataiku DSS 5.x, this is the easiest setup), and click on CREATE. This step can take a few dozens of seconds.
You may have to reload the tab in your web browser (by pressing F5) to see the newly installed plugin.
Usage
Go to the Flow of your project, click on the button +DATASET, and then click on Plugin SPARQL in the Plugins part.
On the next screen, specify the URL of the SPARQL endpoint you want to call, and your query.
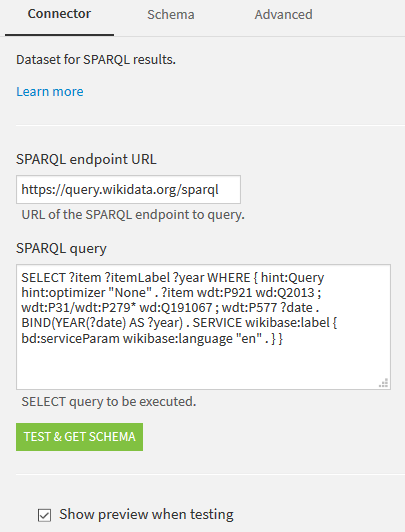
Click on TEST & GET SCHEMA. The query is executed and you will have a preview of the data:
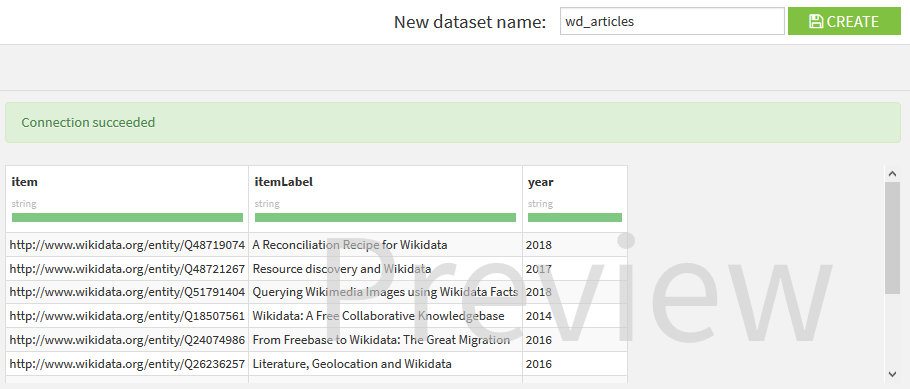
Choose a name for your dataset and click on CREATE.
That’s all, you can now use the data in your Dataiku DSS project 🙂
Under the hood
Dataiku provides a nice tutorial on how to write a DSS plugin.
Connector
The connector is basically a simple Python class. It relies on the SPARQL wrapper from RDFlib, and specifically from the class SPARQLWrapper2, to query the SPARQL endpoint and yield the results to Dataiku DSS.
Code environment
As the connector has a dependency, the plugin contains the definition of a code environment, which holds the list of packages required to work. This avoids the need to install the dependencies by hand, and ensures that the plugin will run in the proper environment.
Example
Let’s get all articles about Wikidata, in Wikidata. The URL of the Wikidata SPARQL endpoint is:
https://query.wikidata.org/sparql
The query:
SELECT ?item ?itemLabel ?year WHERE {
hint:Query hint:optimizer "None" .
?item wdt:P921 wd:Q2013 ; wdt:P31/wdt:P279* wd:Q191067 ; wdt:P577 ?date .
BIND(YEAR(?date) AS ?year) .
SERVICE wikibase:label { bd:serviceParam wikibase:language "en" . }
}
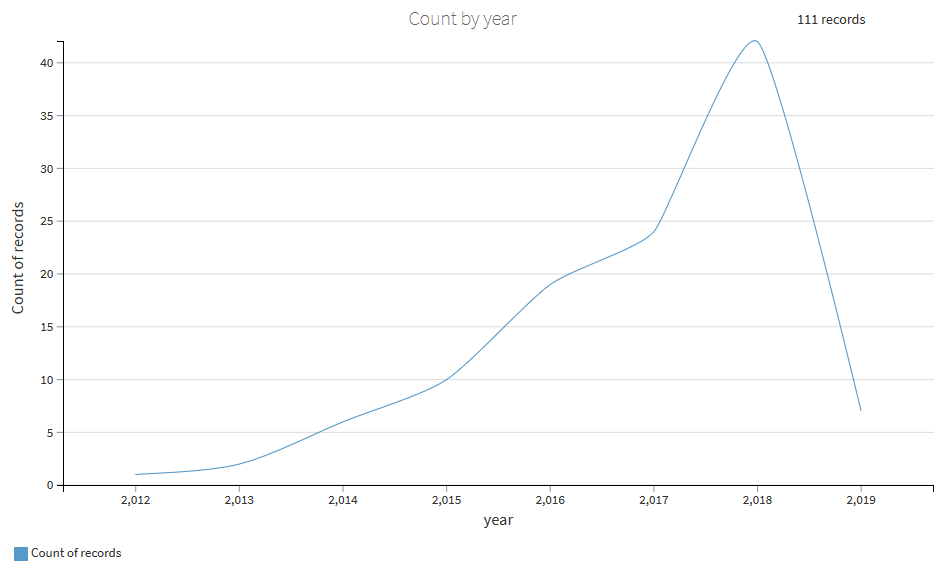
By following the Usage section of this post, you can retrieve the data. Then, you can display a chart with the evolution over time of the number of articles about Wikidata:
A more advanced example is available: Matching BnF and Wikidata video games using Dataiku DSS.